https://research.google/pubs/pub43864/
The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order D
Unbounded, unordered, global-scale datasets are increasingly common in day-to-day business (e.g. Web logs, mobile usage statistics, and sensor networks). At the same time, consumers of these datasets have evolved sophisticated requirements, such as event-t
research.google
구글 리서치 팀에서 발표한 논문이며, streaming 서비스를 구축할 때 필요한 접근법을 구축한 논문이다.
#해당 논문을 정리한 내용
1. Dataflow 란 무엇인가?
직역 그대로 데이터의 흐름이다.
사용자가 웹브라우저에서 이벤트를 발생시키는 순간부터 각 시스템에 도착해 process를 하는 일련의 데이터 이동 과정을 Dataflow로 이해하면 된다.
말은 쉽지만 실상 시스템 네트워크 상에서는 아주 복잡한 문제를 야기한다. 예시로 시스템 상의 어쩔 수 없는 문제(scheduler, network latency, ...)등으로 인해 지연(latency)가 발생한다.
다시 말하자면, 사용자는 1시 30분 0초에 홈페이지를 클릭을 했지만 사실 상 서버에서 process를 처리할 때 데이터가 1시 30분 0초에 도착하는 것을 보장할 수 없다. 특정 문제로 인해 서버에서는 1시 30분 2초에 데이터가 도착했다고 받아 들일 수 있다.
이러한 현상이 수많은 데이터에서 발생한다고 하면 이는 실상 서비스에서 여러 문제점들을 초래할 것이다.
따라서, 우리는 이제 데이터의 흐름이라는 단어를 단순히 데이터 자체만으로 생각하면 안된다. 이것을 넘어서서 "시간"이라는 개념을 포함시켜서 생각해야 한다.
2. Dataflow Model 이란 무엇인가?
위에서 언급한 Dataflow에 발생하는 문제점들을 다루기 위해 만들어진 "접근법"이라 생각하면 된다. 다시 강조해서 말하자면, 해당 Model은 문제점들을 해결하는 solution이 아니다. 문제점을 다루기 위해 개념들을 정립하고 이론을 구축한 model일 뿐이다.
이러한 모델을 이용해서 서비스의 latency와 correctness를 보다 구체화하여 접근할 수 있는 "접근법"이라 생각하면 된다.
3. Dataflow Model의 필요성
현대에는 무한한(unbounded data) 데이터(e.g. web logs, sensor networks.. 등)가 막대하게 증가하기 시작했으며 이를 관리하는 공통의 접근법(framework)의 필요성이 부각되었다.
또한, 경영진 입장에서 실시간 데이터 분석 결과를 보여주는 것이 중요해졌다. 예로, 사업가의 입장에서 그때 그때의 사용자들의 데이터들을 분석하여 기업의 방향성을 수정하거나 마케팅을 해야 하는 경우가 있다. 하지만 데이터의 지연으로 인해 올바른 정보가 그때 그때 분석이 되지 않는다면 이는 기업 입장에서 올바른 결정을 내릴 수가 없게 된다.
따라서, 이러한 The Dataflow Model은 꼭 필요하다.
데이터 구축 단계에서 3가지 특징(Correctness, Cost, Latency)을 생각할 수 있다.
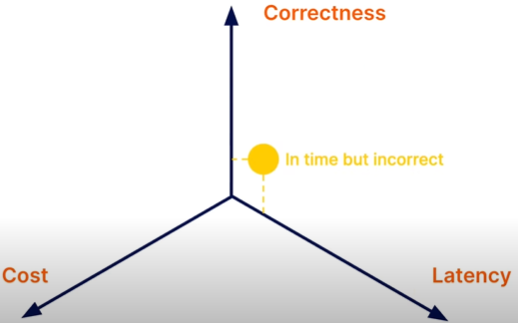
시스템 상 정확한 서비스를 구축하려면 latency가 발생하며, real time을 구현하려면 정확성이 떨어진다. 즉, tradeoff가 발생한다. Dataflow model은 이러한 관점들을 고려하여 해당 문제들을 다루기 위해 만들어진 "접근법"이다.
4. Dataflow Model의 중요 개념
4.1 Time domains
4.1.1 Event time: 이벤트가 실제로 발생한 시간이다.(e.g. 사용자가 웹페이지를 클릭하는 그 순간 시간)
4.1.2 Processing Time: 해당 이벤트가 데이터를 처리하는 파이프 라인으로 넘어와서, 파이프 라인이 해당 이벤트를 process하는 시점이다.
아래의 그림을 보면 더욱 이해하기 쉬울 것이다.
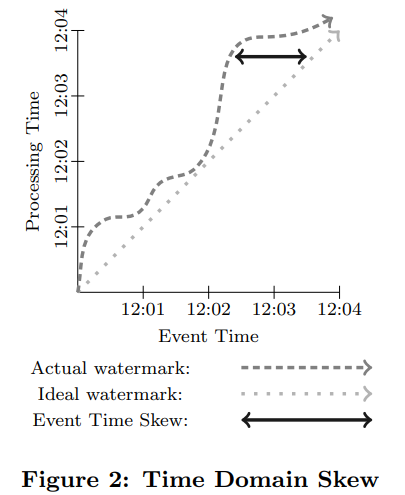
X-axis는 Event time을 의미하며 %분:%초를 의미한다.
Y-axis는 Processing time을 의미하며 마찬가지로 %분:%초를 의미한다.
watermark는 일단 "process 를 실행하는 시점"이라고 생각해두면 편하다(원래는 엄연히 다르다).
실제 가장 이상적인(불가능한) 서비스 구축은 Ideal watermark 표시대로 작동 된다. Event 가 발생하는 시점과 process 시점이 동일하다.
하지만, 실제 상황에서는 Actual watermark 처럼 작용한다. Event time보다 더 늦은 시간에 processing time이 발생한다. 이러한 skew 현상으로 인해 실제 서비스에서 많은 문제점을 초래한다.
극단적인 예시로, 만약 오로지 실시간으로 들어온 데이터들만 그때 그때 분석을 하게 된다면, 조금이라도 지연된 데이터는 영원히 분석되지 않는 문제점들이 발생한다.
이러한 문제를 다루기 위해 Model에서는 새로운 개념 Windowing, Triggering을 정립했다. 우선 아래의 새로운 4가지 개념을 이해하고 그 후에 이러한 문제점들을 어떻게 처리하는지에 대해서 section 4.6 에서 설명을 하겠다. 다시 강조하지만, 문제점을 해결하는 것이 아니다. 문제점을 처리하는 방식 및 접근법인 것이다.
4.2 Bounded data 설명
유한한 데이터 셋을 의미한다. e.g. Machine learning training 과정에서 사용할 데이터 셋처럼 유한한 혹은 고정된 데이터 셋을 의미한다.
4.3 Unbounded data 설명
무한한 데이터 셋, 즉 끝이 없는 데이터 셋을 의미한다. e.g. Web logs 데이터, sensor 데이터 처럼 끊임없이 지속적으로 들어오는 데이터 셋을 뜻한다.
4.4 Windowing 설명
기본적인 설명: Event data를 수집하여 Event time을 기준으로 그룹화 시키는 작업을 windowing이라 일컫는다. 따라서 데이터에는 반드시 timestamp가 기록되어있어야 한다.
아래 [그림 3]을 통해 window라는 개념을 이해할 수 있다. 시간의 흐름 별로 데이터들이 나열 되어있으며, 데이터를 그룹화 시킨 것을 window라 불린다.
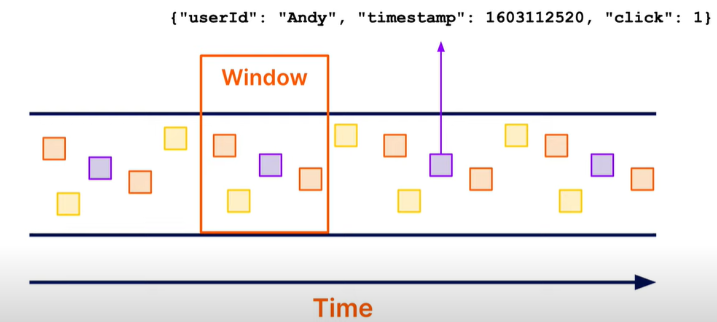
Windowing에는 대표적으로 3가지 window 방식이 존재한다. Fixed window, Sliding window, Sessions window가 존재한다. 각각 하나씩 살펴보도록 하자.
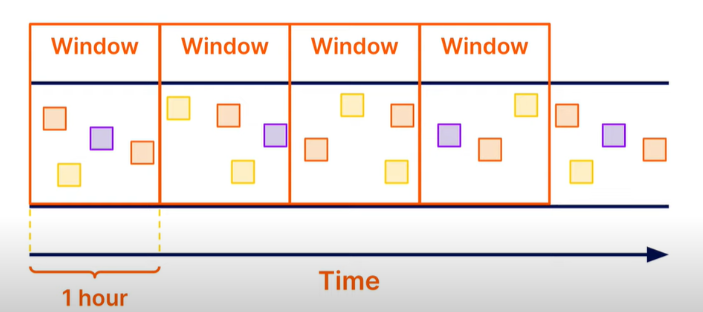
4.4.1 Fixed window
아래 [그림 4]은 Fixed window이며 고정된 시간만큼 데이터를 그룹화(windowing)한다. 따라서, 1시간 전에 발생한 데이터와 1시간 후에 발생한 데이터는 서로 다른 window에 존재하게 된다.
4.4.2 Sliding window
위의 [그림 4]에서 소개된 Fixed window를 1분 씩 이동 시켜서 windowing을 진행한다. 이는 하나의 데이터가 여러 window에 존재할 수 있다.
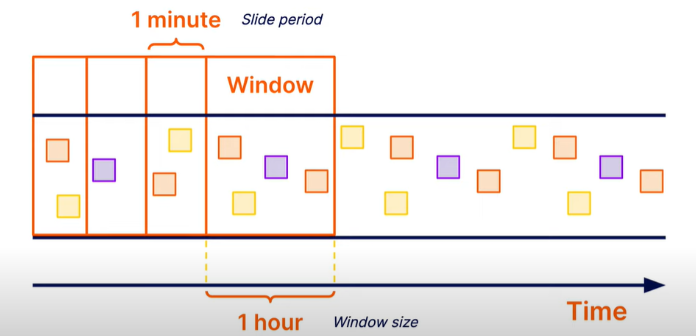
4.4.3 Sessions
위의 [ 그림 4], [그림 5]는 데이터 셋을 구분 짓지 않고 windowing을 진행 했다. 하지만 Session window의 경우는 각 데이터 별로 grouping을 각각 진행을 하며, 특정 시간의 gap마다 windowing을 진행하게 된다. 아래의 그림을 보면 User #1의 데이터 셋의 windowing이 한번 끝나면 30분 후에 새로운 windowing을 진행한다. 그 과정은 User별로 각각 발생한다.
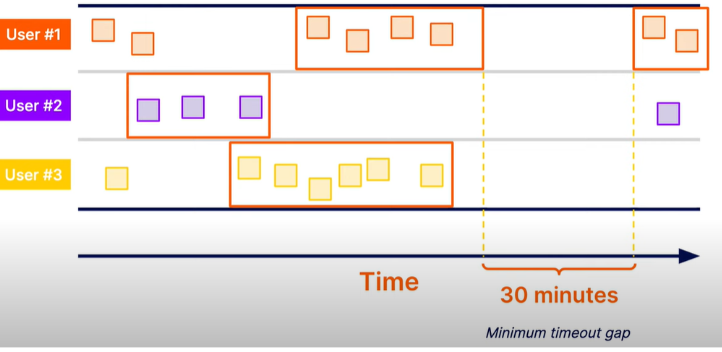
지금까지 대표적인 3가지의 windowing 방식에 대해 살펴보았다. 요약하자면, windowing은 데이터를 그룹화 한다고 생각하면 된다.
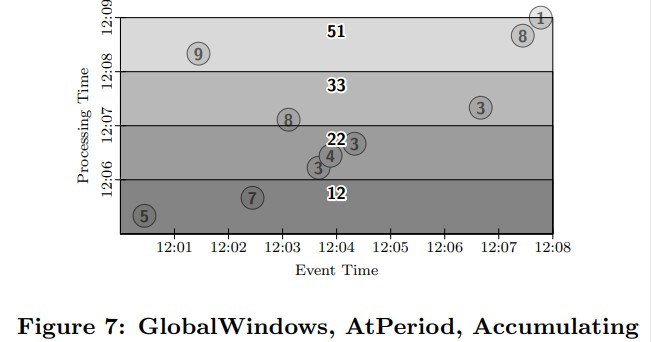
하지만 아래 [그림 7] 과 같은 경우는 숫자 9의 데이터가 뒤늦게 들어오게 된 경우이다. 하지만 [그림 7]의 watermark로써는 해당 숫자 9 데이터는 영원히 process를 진행하지 않게 된다.
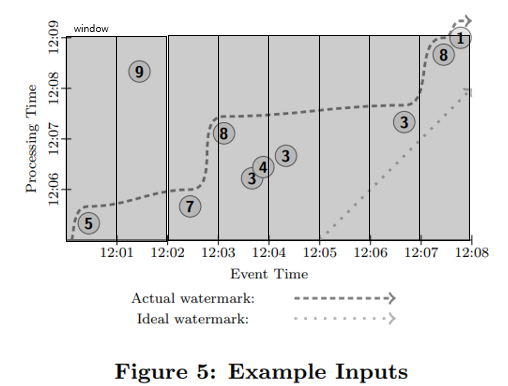
이러한 문제를 다루기 위해 Triggering이라는 개념이 나타났다.
4.5 Triggering 설명
기본적인 설명: process 시기가 결정되어 데이터를 처리하는 시점으로 생각하면 된다.
Windowing과 구별되는 점 Triggering: Windowing은 event time이 기준이며, Triggering은 process time이 기준이다.
4.6 Windowing & Triggering 으로 bounded or unbounded data 처리.
이제부터 예시로 통해 보다 구체적으로 이해해보도록 한다. 이 예시들은 어떤 방법이 더 옳고 좋음을 뜻하는 것이 아닌 그저 방식이 있다는 것을 보여준다.
예시의 가정 사항: 데이터는 총 10개 이며 process function은 summation이다. 마지막 결과는 51이 산출되어야 한다.
watermark: watermark 부분을 지나치면 watermark 아래 영역의 window가 process(summation)이 된다.
예시1. Bounded data & batch engine의 예시
로직의 순서는 다음과 같다.
Step1. 모든 데이터가 들어올 때 까지 기다린다. (모든 데이터가 들어 왔는지에 대해서는 어떻게 알까? : process측에서 10개의 데이터가 들어온 것을 확인)
Step2. 모든 데이터를 하나로 그룹화(windowing) 시킨다.( 이 말은 window가 1개이며 global window를 뜻한다 아래 그림을 보면 색깔 칠해진 box는 하나 밖에 없다.)
Step3. Triggering은 모든 데이터가 도착했을 때 window를 process(summation)을 진행하여 51의 결과 값을 산출한다.
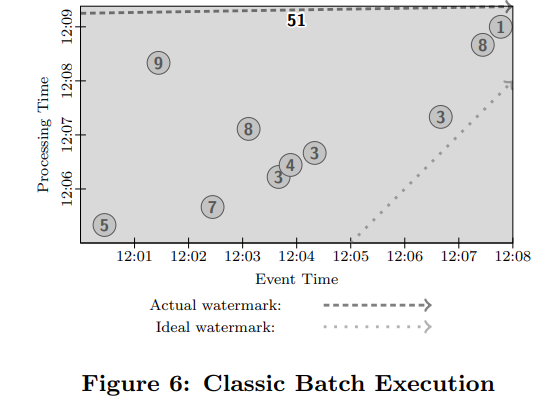
예시2. unbounded data & batch engine의 예시
위의 예제에서 unbounded data(infinite data) 일 경우는 데이터가 언제 모든 데이터가 들어오는지 알 수 없기 때문에 예시1의 step2 과정을 진행할 수가 없다.
따라서, 이 예제2에서는 아래 [그림 9]번처럼 1분마다 global windowing이 진행되며 summation을 하는 Triggering이 발생한다. 그리고 1분마다 결과 값들을 업데이트 해나간다. 결국에는 예제1번과 같이 결과 값 51이 산출된다.
로직의 순서는 다음과 같다.
Triggering은 1분마다 발생한다.
Step1. Triggering이 발생할 때마다 global window로 데이터를 그룹화해서 summation을 진행한다. 따라서 처음엔 12:06에는 5+7= 12의 결과 값이 산출한다.
Step2. 다음 1분인 12:07분에 Triggering이 발생하여 global window로 데이터를 그룹화해서 summation을 진행한다. 5+7+3+4+3 = 22의 결과 값이 산출된다.
StepN. 위의 Step1,2를 반복하여 결국엔 51의 결과 값이 산출된다.
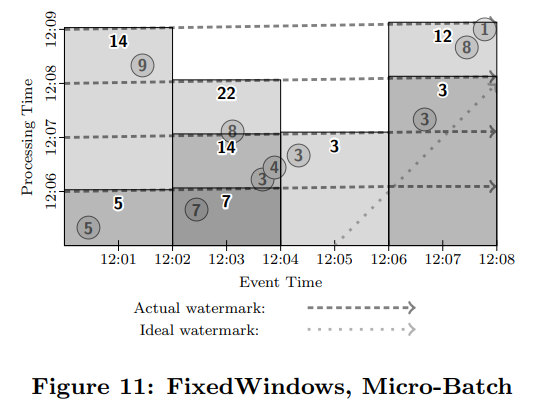
예시3. unbounded data & batch engine의 예시
위의 예시1,2은 global window를 사용해서 process를 진행했지만, 예시3번의 경우는 Fixed windows를 사용하며 micro-batch 단위로 process를 진행한 예시이다. 즉, 데이터 그룹화는 Event time 기준 2분마다 windowing 이 진행되며 Triggering은 1분마다 발생한다.
Window는 총 4개로
Window1 : 12:00 ~ 12:02 구간의 데이터 그룹
Window2: 12:02 ~ 12:04 구간의 데이터 그룹
Window3: 12:04 ~ 12:06 구간의 데이터 그룹
Window4: 12:06 ~ 12:08 구간의 데이터 그룹
으로 형성이 된다.
로직의 순서는 다음과 같다.
Step1. Fixed window 방식으로 데이터를 그룹화 한다.
Step2. 12:06분에 첫번째 Triggering이 발생하여 window1, window2에 대해 각각 summation을 작업한다. 그 결과 window1에서는 5의 값, window2에서는 7의 값이 산출된다.
Step3. 12:07분에 두번째 Triggering이 발생하여 window1, window2, window3에 대해 summation이 진행된다. 그 결과 window1에서는 5의 값, window2에서는 14의 값, window3에서는 3의 값이 산출 된다.
StenN. Step1~3를 반복하여 결국에 4개의 window에서 summation 결과 값들이 산출된다. 이들을 모두 합하게 되면 51의 최종 결과 값이 산출된다.
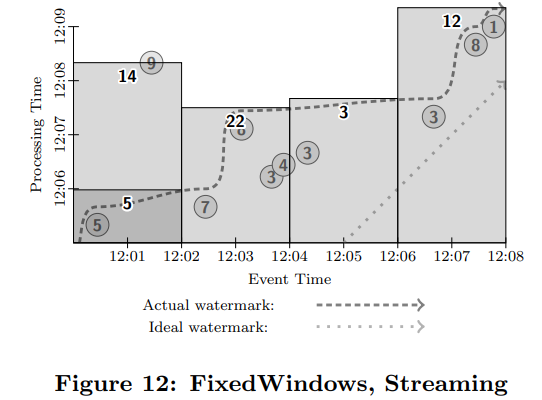
예시4. unbounded data & streaming engine의 예시
Window는 예시3번과 똑같이 진행되어 데이터 그룹화를 진행한다. 하지만 Triggering 방식이 다르다. Watermark 가 지나치면 process가 바로 진행되어 결과 값을 산출한다. 하지만 [그림 11]의 경우 "숫자 9"의 데이터가 watermark 보다 늦게 도착하게 된다. 이 경우, 그냥 무시하고 일단 지나가면서 계산한다. 그리고 "숫자 9"가 도착했을 때 retriggering을 진행하여 window1의 summation 결과 값을 update 한다.
5. Recap
The Dataflow model은 파이프라인을 4단계로 분해해서 분석한 작업이다.
- What results are being computed.
- Where in event time they are being computed.
- When in processing time they are materialized.
- How earlier results relate to later refinements.
위의 문제를 다루기 위해서 Windowing , Triggering 개념을 정립했으며 데이터에 대해 보다 명확한 접근법이 Dataflow model 이다.
따라서, 우리는 이러한 모델을 기반으로 파이프 라인 설계 및 구현을 해야 한다.
출처:
https://www.youtube.com/watch?v=yZUe4th9gwY
https://www.youtube.com/watch?v=E1k0B9LN46M
'MLOps' 카테고리의 다른 글
| TFX Guide Local pipeline example (0) | 2022.04.25 |
|---|---|
| Practitioners guide to MLOps (0) | 2022.04.25 |
| TFX paper (0) | 2022.04.22 |
| Kubernetes 자격증(CKAD) 준비 (0) | 2022.04.19 |
| ML pipeline 이란? (0) | 2022.04.18 |