https://arxiv.org/abs/1906.00091
Deep Learning Recommendation Model for Personalization and Recommendation Systems
With the advent of deep learning, neural network-based recommendation models have emerged as an important tool for tackling personalization and recommendation tasks. These networks differ significantly from other deep learning networks due to their need to
arxiv.org
*Framework: Pytorch, Caffe2
*Categorical feature를 잘 다룸 -(How?)-> embedding 방식을 통해서 다룬다.
*데이터:
synthetic dataset: 실제 병목현상을 파악하기 위해서 만들어낸 데이터 (만들어내는 과정은 논문에 있음)
public dataset: 성능 측정을 위한 데이터( Criteo AI Labs Ad Kaggle and Terabyte datasets)
이거 모델에 대한 자세한 내용은 없다... 논문에서 리뷰과정을 통해서 설명하는게 더 이해하기 쉽다는 이유로... 자세한 내용을 적지 않았다. 뭐 이런.....경우는 처음보네... review 과정에 대한 document도 찾아볼 수 없다....
대신 모델에 사용되는 가장 중요한 4가지 기술에 대해 언급한다...... *그냥 개념 설명이지, 해당 개념이 어떻게 사용되었는지는 설명이 안되어있다...........!!!!

[핵심기술 4가지]
1. Embeddings
2. Matrix Factorization
3. Factorization Machine
4. Multilayer Perceptrons
#DLRM Architecture
그래도 다행히(?) 아키텍처의 순서정도는 설명이 되어있다.
(1) categorical features -> embedding vector
(2) continuous features -> MLP (vector size: same as embedding vector for categorical feature)
(3) dot product between (1) and (2) features
(4) 다시 MLP 모델에 들어감
(5) sigmoid function으로 확률값 return
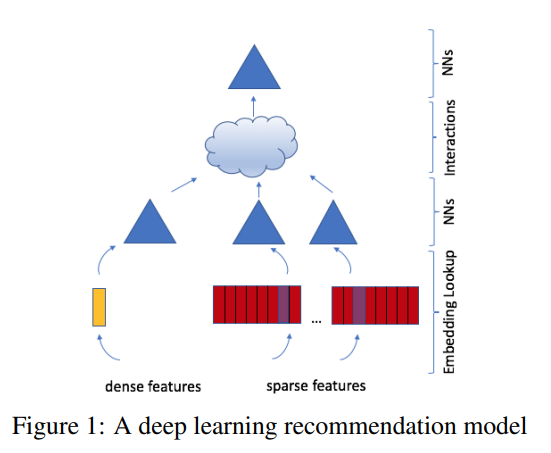
Wide and Deep Model과 거의 흡사한 구조이다.(특징점은 W&D model은 cross product, DLRM은 dot product)
요약하자면, Sparse한 데이터를 가지고 있는 categorical features는 embedding을 통해서 보완하고 continuous features는 MLP에 바로 던져 넣는다. 그리고, 두개의 categorical features와 continous features들을 dot product 을 concatenate해서 MLP을 통해 학습.
